-한국전자통신연구원(ETRI), 한국어 특화 언어모델 공개
-구글의 언어모델보다 뛰어난 성능 입증
-향후 다양하게 활용될 수 있어

[데일리비즈온 김소윤 기자] 세계적으로 인공지능(AI)에 대한 연구가 활발한 가운데 우리나라에서 구글보다 뛰어난 AI 한국어 특화 언어모델이 공개됐다.
지난 10일 한국전자통신연구원(ETRI)가 홈페이지를 통해 공개한 ‘코버트’는 ETRI가 AI 서비스 개발을 위해 독자적으로 구축한 한국어 특화 딥러닝 언어모델이다. 사람이 하는 말을 정확히 이해하고 그에 맞는 대답을 찾도록 돕는 AI다.
이 AI는 기존에 나온 구글의 한국어모델보다 인식 성능이 5% 가까이 뛰어나다. 질의응답이나 문장 내 개체 역할 인식 등의 성능이 좋았다.
이 모델이 수행하는 원동력은 AI 기술의 일종인 딥러닝이다. 딥러닝 기술은 AI의 방대한 학습능력의 비결이다. 딥러닝 기술을 이용해 의사보다 뛰어난 AI와 유명한 바둑 기사를 이기는 AI가 탄생되는 것이다.
언어모델의 경우 AI가 언어를 학습하도록 구축된 데이터베이스다. AI는 언어를 숫자로 표현하고 딥러닝으로 인식한다. 이 학습 과정에서 일정 단어가 특정한 조건에서 얼마나 자주 나타나는지 등에 여부를 확률로 계산해 언어와 함께 모였다.
이를테면 ‘날씨’라는 단어 다음 ‘어때’가 올 확률과 그 이후 대답에 ‘나빠’가 올 확률 등이 단어와 함께 기록한 데이터를 학습하는 것이다. ‘날씨 어때’라는 말에 ‘재밌어’라는 답을 하지 않고 ‘좋아’ 혹은 ‘나빠’라고 답해야 된다는 것을 딥러닝을 이용해 학습하는 것이다.
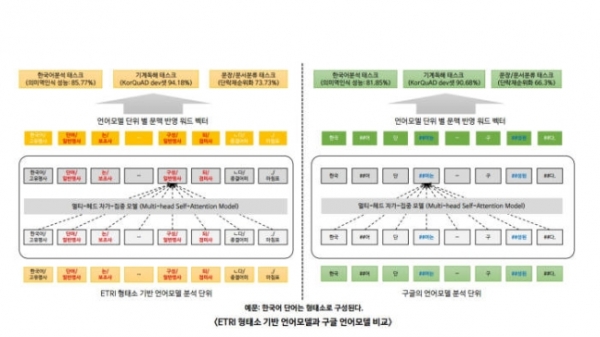
원래 그간 구글의 다국어 언어모델 버트(BERT)가 이용돼왔다. 버트는 문장 내 어절을 한 글자씩 끊은 뒤 서로 연결시켜 앞뒤로 자주 만나는 글자를 단어로 인식한다. ‘날씨 어때’를 예로 들면 ‘날씨’ '씨어’ ‘어때’를 각각 비교해 자주 조합되는 ‘날씨’와 ‘어때’를 단어로 보고 끊어 읽는 식이다. 버트는 40만 건 이상의 위키백과 문서 데이터를 이런 식으로 학습한 구글이 개발한 한국어 언어모델이다.
이번에 공개된 코버트는 구글의 버트의 업그레이드 버전이라고 보면 된다. 한국어 특성에 맞게 개선한 것이다. 구체적으로 기존 데이터 외 최근 10년 간 신문기사, 백과사전 데이터 23기가바이트(GB)를 추가로 학습시켜 학습량(학습한 형태소의 수, 45억 개)을 늘렸다.
아울러 ‘날씨가 어때’의 ‘가’처럼 조사가 붙는 한국어의 문법 특성을 반영해, 사전에 형태소를 분석하는 과정을 추가했다. 총체적인 딥러닝 학습 과정도 한국어 조합에 맞게 구성했다.

실제 성능 분석 결과 ETRI는 이렇게 완성한 코버트의 성능이 기존의 구글 버트보다 뛰어나다고 밝혔다. ETRI는 자체적으로 성능 분석해보니 코버트는 문서의 주제를 분류하거나 문장 유사도를 추론하는 시험, 문장 내에 등장하는 인물의 역할을 인식하는 시험, 질문에 제대로 대답을 하는 시험 등 5개 평가 항목에서 버트보다 평균 4.5% 높은 점수를 기록했다고 전했다.
뿐만 아니라 질문에 대해 답을 검색 후 정답이 있는 단락의 순위를 매기는 시험의 경우 구글 대비 7.4% 뛰어난 점수를 보였다. 한국어 질의응답에 최적화된 언어모델을 수치로 증명한 셈이다.
이같이 개선된 언어 구사 능력을 가진 코버트는 향후 AI비서나 질의응답 등에 활용될 것으로 전망된다. 연구팀도 코버트가 한국어에 최적화된 언어모델을 통해 한국어 분석, 지식추론, 질의응답 등 다양한 한국어 딥러닝 기술이 향상될 것을 기대하고 있다.
이와 더불어 활용도도 높아질 전망이다. ‘공공AI오픈API’ 데이터 서브스 포털에 공개했고 기존 딥러닝 프레임워크인 텐서플로우 등에서 활용이 가능하기 때문이다. 이에 기업과 연구기관 개발자를 포함해 학생을 가르치는 상황 등에도 활용될 수 있다.
앞으로도 연구팀은 좀 더 긴 데이터를 한 번에 처리하는 한국어 모델을 개발할 계획이다. 이로 인해 버트 모델의 근본적인 한계도 극복한다는 방침이다. 코버트의 한계로는 512개 이상의 단어가 들어간 문서를 한 번에 처리하지 못한다는 점이 있다. 또한 데이터 검증 방법도 추가로 개선할 계획이다.
한편 코버트는 대표적인 딥러닝 프레임워크 파이토치(PyTorch)와 텐서플로(Tensorflow) 환경 모두에서 사용 가능하다. ETRI에 따르면 이번 연구 성과 배경으로 과학기술정보통신부와 정보통신기획평가원(IITP) 혁신성장동력 프로젝트 엑소브레인(Exobrain) 사업이 거론된다. 엑소브레인은 ‘내 몸 밖의 인공두뇌’라는 뜻을 내포했다. 자연어 이해를 바탕으로 지식을 학습해 사람과 질의응답하는 AI 기술이다.